How to generate a concordance?
Log in to Sketch Engine (or click Home) and select a corpus. Then, in the left menu, click Search to display the following screen:

if you see more options, close them by clicking on the underlined links or proceed to advanced options further below
(2) type your keyword or a phrase and click (3) make concordance
The results can be sorted and filtered, frequencies can be calculated. See Working with concordance results More precise search criteria can used by following the information below.
VIDEO: making a concordance
Watch this short You Tube video to see how you can generate a concordance in Sketch Engine.
Concordance Search – advanced options
Click (2) Query types and/or Context and/or Text types links to unfold the related options.

(2) Query types
Query types - screenshot
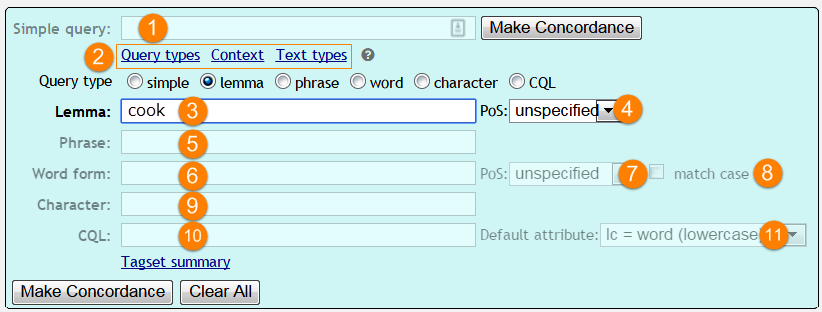
Click Query types to unfold a list of available queries. Start typing into the required box, the type will be selected automatically and will be highlighted, the others will appear in grey. In the screenshot above the user decided to use the lemma search.
simple
The simple search tries to guess what you wanted to do:
- if you type a lemma, it behaves as a lemma search with PoS:unspecified
e.g. typing bear will find all forms, i.e. bear (animal) but also bear (verb), bore, born, bearing - if you type a word form which is not a lemma, it behaves as word form search
e.g. typing goes will only find examples of goes - if you type two or more words which are lemmas, it will try to find all word forms
e.g. typing drive them will find driving them, drove them, drives them, drive them - if you type a word which contains a word form which is not a lemma, it behaves as the phrase search.
e.g. typing goes home will only find examples of the phrase but not examples of went home - if you search a word or phrase containing an apostrophe, you have to type the part with the apostrophe separately.
e.g. typing Jane ‘s will find Jane’s or he ‘s will find he’s - if you search contracted negative forms, the apostrophe is not separately.
e.g. typing must n’t will find mustn’t or must not will find must
Wild cards are allowed. The simple search is always case insensitive. (There might be rare cases when the corpus author configured the corpus differently.)
lemma
- will find all word forms of the word, i.e. searching for go will find go, goes, going, went, gone
- produces no result if the search word is not a lemma, e.g. typing goes produces no results
- only one lemma is allowed, to search for a sequence of lemmas, use CQL
- when PoS is set to unspecified, all parts of speech will be included if the lemma corresponds to more than one PoS, e.g. searching for bear with PoS:unspecified will find both examples of the animal as well as the verb to bear
phrase
- will find examples of a sequence of tokens exactly as it is typed, differences in spaces are ignored, i.e. in bed will produce the same results as in bed
- is case sensitive, i.e. buy an apple will produce different results from by an Apple
- regular expressions are allowed, e.g. constr.* will find all words starting with constr
- if you need to search for punctuation, e.g. to find Hallo?, use CQL because punctuation constitute a separate token and some punctuation marks are operators in regular expressions, thus searching for hallo? would find examples of the word hall and hallo (the use of ? makes the letter o optional)
word form
will find the exact word form as it is typed, i.e. goes will only find examples of goes but not examples of go, went, going, etc.
regular expressions are allowed, i.e. un.*ous will find examples of all words starting with un and ending with ous with any number of characters in between
character
will find a sequence of characters inside a token
CQL - Corpus Query Language
used for complex searches including searching for structures without specifying concrete words
the advanced concordance above was generated from the British National Corpus with this CQL query:
[lemma=”grow”] []{0,3} ~8″tomato-n”
which tells Sketch Engine to find this:
[lemma=”grow”] finds all occurences of lemma grow
[]{0,3} followed by between zero and three random tokens (words)
~8″tomato-n” finds 8 words most similar to tomato (uses the thesaurus)
(2) Context
Activate the context options by clicking the Context link. The context options can be used together with Query types and Text types options.
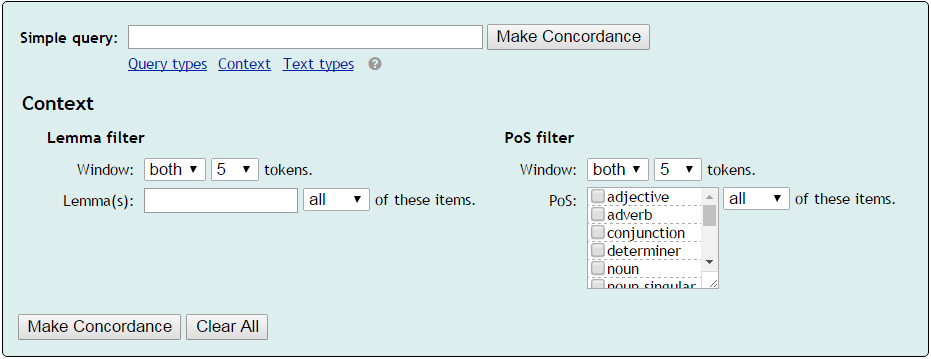
Lemma filter
in the screenshot, the user is looking for the lemma rather but wants to avoid examples of would rather or should rather so the context is specified as:
- 1 token to the left of the search word
- neither would nor should should appear (lemmas must be separated by the vertical bar “|”, e.g. would|should)
window can be set to left, right or both
tokens specify a window, not an exact position, when set to 4, it means between 1 and 4 tokens from the search word
none of these items – no lemma should appear
any of these items – at least one of the lemmas must appear in the window
all of these itmes – all of these lemmas must appear in the window (not necessarily in the same order)
PoS filter
The part of speech filter can be used to include or exclude certain parts of speech from the context of the word.
In the screenshot, the user excluded adverbs and adjectives one token to the right of rather.
window can be set to left, right or both
tokens specify a window, not an exact position, when set to 4, it means between 1 and 4 tokens from the search word
none of these items – none of the ticked PoS should appear
any of these items – at least one of the ticked PoS must appear in the window
all of these itmes – all of the ticked PoS must appear in the window
Result
The query found the less frequent uses of the word rather, excluding examples of
would rather
should rather
rather + adjective, e.g. rather long
rather + adverb, e.g. rather quickly
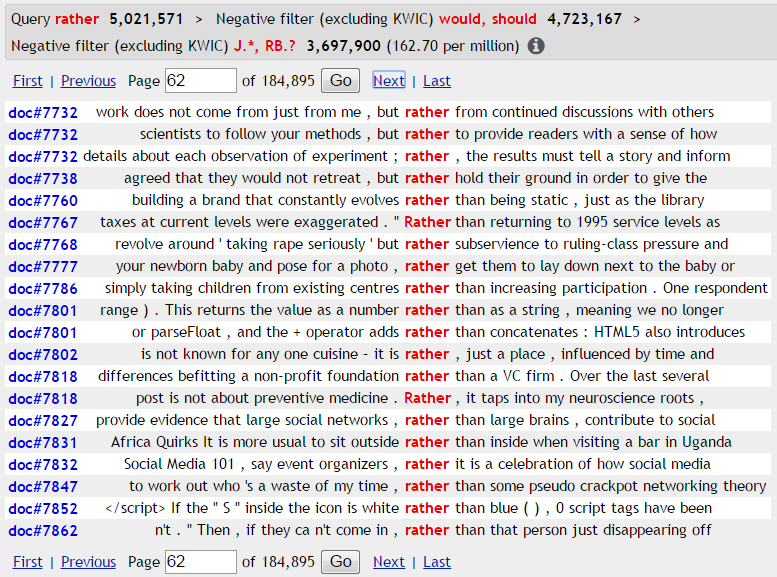
To exclude the rather numerous examples of rather than, it would be necessary to use CQL or to use additional filters on this result screen.
VIDEO: using context with concordances
Watch this You Tube video to learn to use context with concordances:
(2) Text types
Documents in a corpus can (but do not have to) be annotated (labelled) with information indicating the type of text, time of publication, purpose etc. Different corpora contain different type and different quantity of annotation. Corpora without this type annotation will not display any text type options to select.
settings
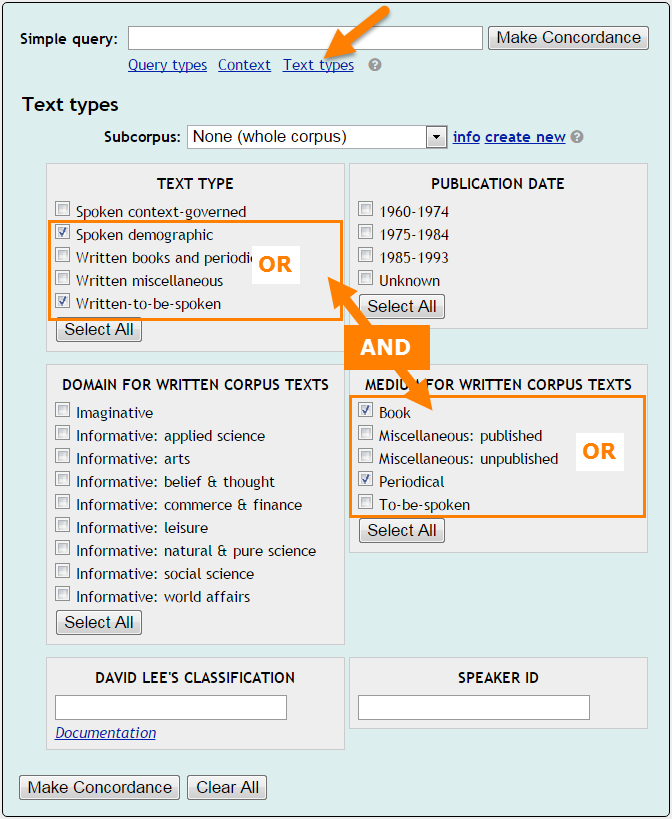
an example of the Text type settings available for the British National Corpus, other corpora can have more, fewer, different or no such settings at all
OR will be used between options from the same group
AND will be used between different groups
The example will be interpreted as:
include documents which are
spoken demographic OR written to be spoken
AND at the same time are
book OR periodical
Constraint on a subcorpus has an effect on the resulting size per million, see what causes the difference in size per million when using Text Type vs. a subcorpus.

