Santa Barbara Corpus of Spoken American English (SBCSAE)
The Santa Barbara Corpus of Spoken American English (SBCSAE) is an English corpus based on a large volume of natural spoken interactions coming from all over the United States. The corpus represents a variety of people of different regional origins, ages, occupations, genders, ethnic and social backgrounds. Such information is also included in metadata, which you can access using the Text Type Analysis function.
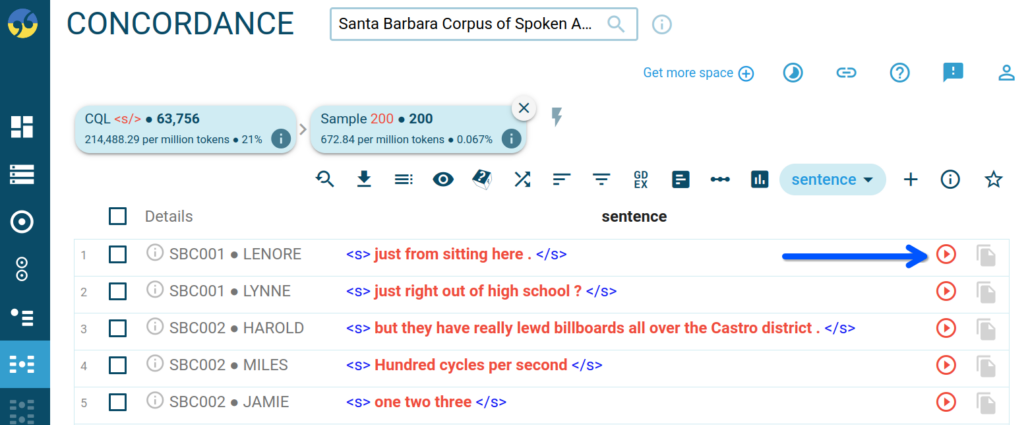
The corpus includes transcriptions as well as audio tracks. To play the audio, please click on the play button (red icon) on the right side of the concordance line. See the screenshot below:
The corpus was created in the Linguistics Department of the University of California, Santa Barbara, under the licence CC BY-ND 3.0 US DEED.
Please refer to the official website for more information: https://www.linguistics.ucsb.edu/research/santa-barbara-corpus
Individual recordings can be found here: https://sla.talkbank.org/TBB/ca/SBCSAE/01.cha
Part-of-speech tagset and lemmatization
The English corpora are part-of-speech tagged with the following English Penn Treebank tagset summary (with Sketch Engine modifications) indicating the part of speech and grammatical category. The corpus texts also contain lemmatization when each word form from the corpus is assigned to its base form (lemma).
Search the Santa Barbara corpus
Sketch Engine offers a range of tools to work with this English corpus.
Santa Barbara Corpus of Spoken American English corpus sizes
| Tokens | 297,247 |
| Words | 249,655 |
| Sentences | 63,756 |
| Transcriptions | 60 |
Tools to work with the Santa Barbara Corpus of Spoken American English corpus
A complete set of Sketch Engine tools is available to work with this English corpus to generate:
- word sketch – English collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word and multi-word units
- word lists – lists of English nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
- concordance – examples in context
- trends – diachronic analysis automatically identifies neologisms and changes in use
- text type analysis – statistics of metadata in the corpus
Changelog
Santa Barbara Corpus of Spoken American English
- version santabarbara (January 2024)
Bibliography
Du Bois, John W., Wallace L. Chafe, Charles Meyer, Sandra A. Thompson, Robert Englebretson, and Nii Martey. 2000-2005. Santa Barbara corpus of spoken American English, Parts 1-4. Philadelphia: Linguistic Data Consortium.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.

