Check the latest version – OpenSubtitles corpora
The OpenSubtitles parallel corpora is a collection consisting of 60 corpora in 58 languages. This corpus collection includes recent texts in a wider range of languages. The OpenSubtitles corpora have been processed with up-to-date tools such as part-of-speech tagging and lemmatization in contrast to this older collection of the OPUS corpora. For more information, visit the OpenSubtitles parallel corpora.
A parallel corpus 40 languages
The OPUS parallel corpora is a set of text corpora with aligned sentences which allow searching and analysing translations between all the languages.
The parallel corpora were collected, prepared and aligned by Jörg Tiedemann in the OPUS project . We are most grateful to him for his great work and co-operation. The data were processed by Sketch Engine using a range of lemmatisers, part-of-speech taggers and sketch grammars.
The OPUS2 corpora are the second version with m:n the alignment, which allows for just one corpus per language.
This parallel corpus can be searched and analysed monolingually or multilingually using all available tools in Sketch Engine: concordances, collocations, word lists and more.
The OPUS project in Sketch Engine contains 40 languages: Afrikaans, Albanian, Arabic, Bosnian, Bulgarian, Chinese (simplified characters), Chinese (traditional characters), Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, German, Greek, Hebrew, Hindi, Hungarian, Italian, Japanese, Korean, Latvian, Lithuanian, Macedonian, Norwegian, Persian, Polish, Portuguese (Brazilian), Portuguese (European), Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swedish, Turkish, Ukrainian.
A list of subcorpora
- ECB – European Central Bank corpus (v.0.1)
- EMEA – European Medicines Agency documents (v.0.3)
- EUconst – The European constitution (v.0.1)
- EUROPARL – European Parliament Proceedings (v.3) [transcripts of spoken language]
- Opensubs – Open Subtitles corpus (v.2) [transcripts of spoken language]
- KDE4 – KDE4 localization files (v.2)
- KDEdoc – KDE manual corpus
- MultiUN – Translated UN documents
- OpenOffice – a collection of documents from http://www.openoffice.org/
- OpenOffice (v.3) – a collection of documents from http://www.openoffice.org/
- OpenSubtitles2011 – Open Subtitles corpus (2011 version) (source: Wayback Machine) [transcripts of spoken language]
- RF – Regeringsförklaringen – Declarations of Government Policy by the Swedish Government
- SETIMES2 – A parallel corpus of the Balkan languages (v.2)
- SPC – Stockholm Parallel Corpora (v.1)
- TEP – The Tehran English-Persian subtitle corpus (v.0.1) [transcripts of spoken language]
- Tatoeba – a collection of translated sentences from Tatoeba
- TedTalks – transcription and translation of TED talks [transcripts of spoken language]
- UN – Translated UN documents
- hrenWaC – Croatian-English Parallel Web Corpus
List of tools & grammar used for various languages
| Language | Tools Used | Grammar |
|---|---|---|
| Arabic | Only shallow tagging part-of-speech tagset | Universal Sketch Grammar with AMIRA Tagset |
| Bulgarian | TreeTagger using UTF-8 Bulgarian parameter file with the following tagset | Yes |
| Chinese (Traditional, Simplified, mixed) | Segmented using Stanford Segmenter modeled on segmentation standards by Chinese Penn Treebank. Tagged using Stanford tagger trained on a combination of Chinese Treebank texts from Chinese and Hong Kong sources with tagset | Universal Sketch Grammar with tags |
| Dutch | TreeTagger using UTF-8 Italian parameter file with the following tagset | Dutch Sketch Grammar (NLWAC tagset) v4.0 by Carole Tiberius |
| English | TreeTagger using UTF-8 English parameter file with the following tagset | English Sketch Grammar v.2.0 (Penn Treebank tagset) by Niels Ott |
| Estonian | TreeTagger using UTF-8 Estonian parameter file with the following tagset | Estonian Sketch Grammar v1.2 by Maria and Jelena |
| French | TreeTagger using UTF-8 French parameter file with the following tagset | French Sketch Grammar v1.0 by Adam Kilgarriff |
| German | TreeTagger using UTF-8 German parameter file with the following tagset | Sketch Grammar for German by Matej Durco v3.3 |
| Italian | TreeTagger using UTF-8 Italian parameter file with the following tagset | Sketch Grammar for Italian v1.2 by Marco Baroni |
| Portuguese | TreeTagger using Pablo Gamalo’s parameter file | Portuguese Wordsketches (Linguateca parsed data) v1.0 by Adam Kilgarriff & DP |
| Russian | TreeTagger using Serge Sharoff’s Russian parameter file (source: Wayback Machine) with the following tagset | Russian Wordsketches v1.0 by Maria Khokhlova |
| Spanish | FreeLing Tagger with the following Tagset | Spanish Wordsketches v1.0 by Nuria Bel and Hada Ross Salazar (Pompeu Fabra University, Barcelona) |
All other languages without tagging tools were just tokenized using Universal tokenizer built by Jan Pomikalek and inspired by Laurent Pointal’s TreeTagger wrapper.
Montenegrin-English corpus from subtitles
The Montenegrin-English parallel corpus consists of movie subtitles. The total number of tokens is 1.07 million. The original data a more information is available on the original website http://opus.nlpl.eu/MontenegrinSubs.php Preprocessing of data was carried out by Nikola Ljubešić.
Reference
Božović, P., Erjavec, T., Tiedemann, J., Ljubešić, N., & Gorjanc. V. (2018). Opus-MontenegrinSubs 1.0: First electronic corpus of the Montenegrin language. In Proceedings of the Conference on Language Technologies & Digital Humanities 2018 (pp. 24-28).
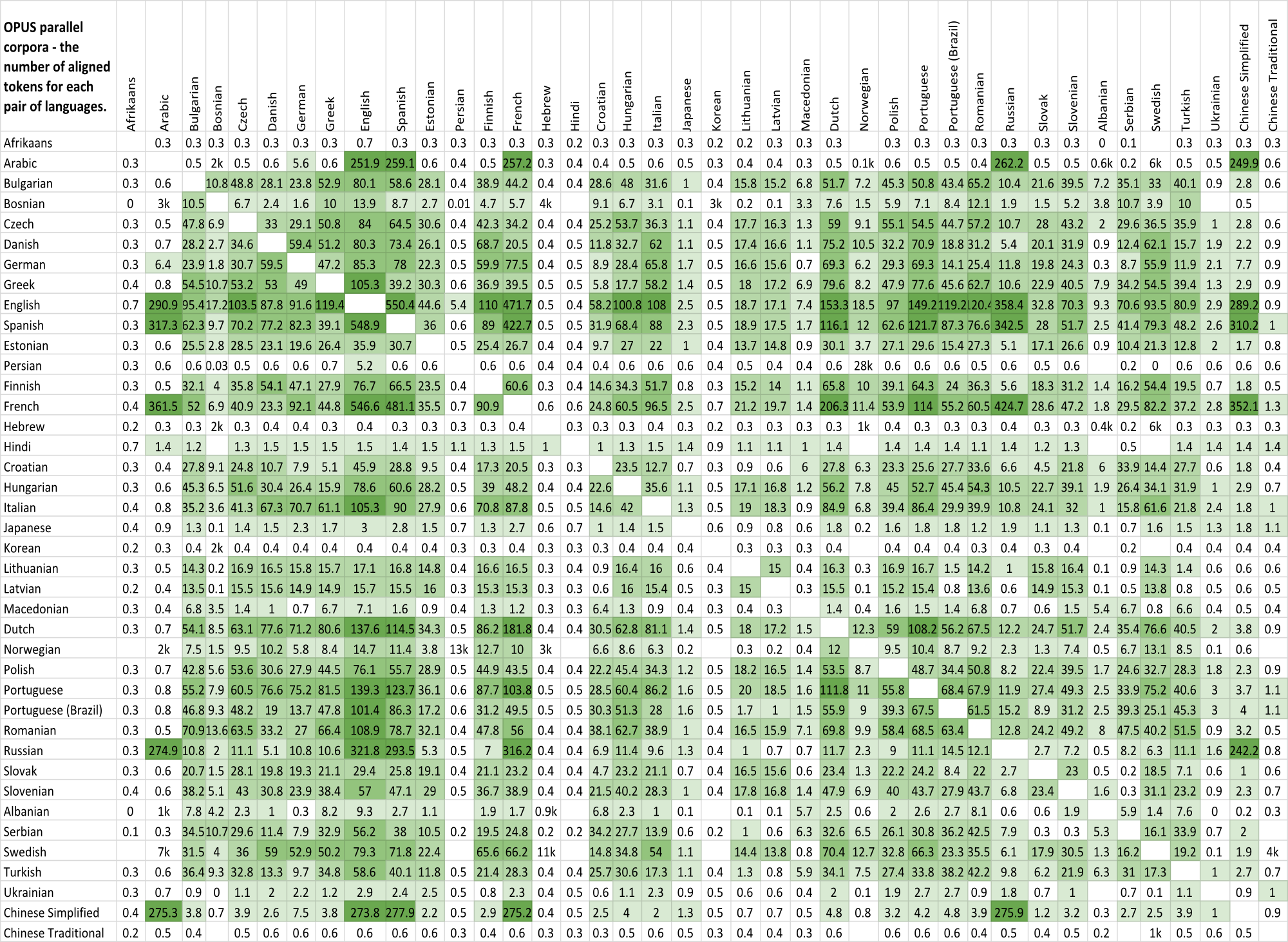
A comparison chart of OPUS parallel corpora
The table shows the number of aligned tokens (in millions) for each pair of languages. Click to enlarge.
Search the OPUS parallel corpora
Sketch Engine offers a range of tools to work with the OPUS parallel corpora.
or
Tip
Create your own multilingual or parallel corpora in Sketch Engine.
See our user guide.
Bibliographic references
Please cite the following article if you use any part of the corpus in your own work:
Jörg Tiedemann, 2012, Parallel Data, Tools and Interfaces in OPUS. [pdf] In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC’2012).
Changelog
version 2 (m:n mapping) 2013
- data alignment changed, each segment is aligned to zero, one or more segments
version 1 (1:1 mapping)
- the alignment of one segment to one segment
Use Sketch Engine in minutes
Generating collocations, frequency lists, examples in contexts, n-grams or extracting terms is easy with Sketch Engine. Use our Quick Start Guide to learn it in minutes.

