Merlin Learner Corpus
MERLIN represents an error-annotated learner corpus encompassing the German, Italian, and Czech languages. Its inception traces back to the MERLIN project, which unfolded between 2012 and 2014. MERLIN’s text samples are sourced from standardized language assessments and adhere rigorously to the Common European Framework of Reference for Languages, as established by the Council of Europe in 2001 and updated in 2020. This platform offers comprehensive access to all corpus texts along with their associated assessments. It elucidates potential applications, whether in educational settings or academic research, while also providing insights into the corpus’s structure and annotation methodology.
The data were used all thanks to the MERLIN project, the website of which provides more information. The MERLIN corpora are also part of the CLARIN infrastructure.
Search the Merlin corpora
Sketch Engine offers a range of tools to work with these Merlin corpora.
Error Analysis feature
The Error analysis function is available in Concordance. This feature is described in more detail here: https://www.sketchengine.eu/documentation/setting-up-learner-corpus/
An example of an error-annotated concordance. The page can be viewed at this link https://ske.li/xfw (login required).
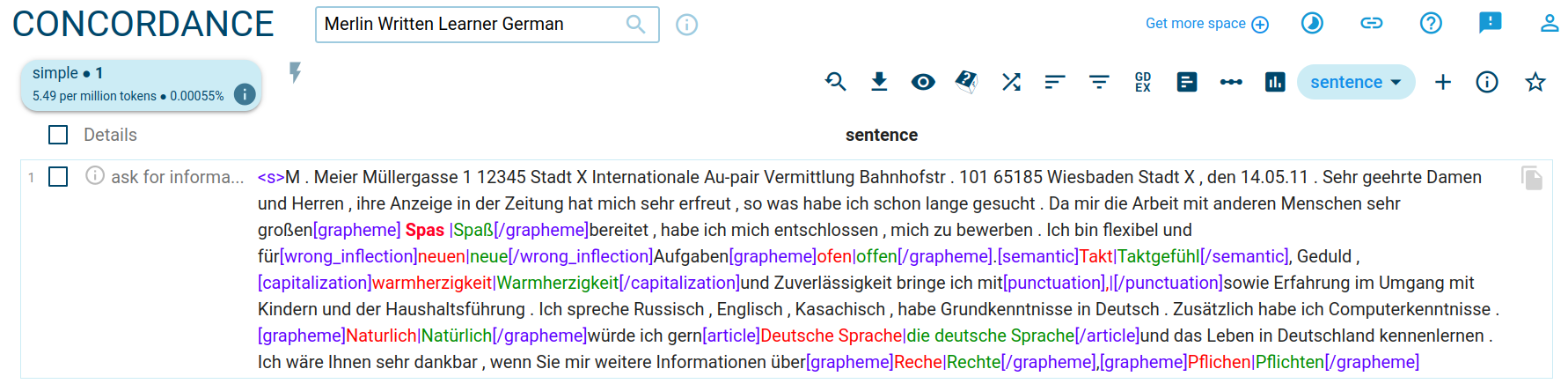
Types of errors
Many errors are annotated, here are some of them:
| Code | Description | Example |
| punctuation | punctuation | [punctuation]Sehr geehrte Damen und Herren|Sehr geehrte Damen und Herren ,[/punctuation] |
| grapheme | grapheme | [grapheme]Anannse|Annonce[/grapheme] |
| preposition | preposition | [preposition]Von|An[/preposition] |
| wrong_inflection | wrong inflection | [wrong_inflection]mich|mir[/wrong_inflection] |
| verb_formation | verb formation | [verb_formation] gelesen |[/verb_formation] |
| capitalization | capitalization | [capitalization]arbeit|Arbeit[/capitalization] |
| article | article | [article]Deutsche Sprache|die deutsche Sprache[/article] |
| semantic | semantic | [semantic]Takt|Taktgefühl[/semantic] |
| word_boundary | word boundary | [word_boundary]Zur Zeit|Zurzeit[/word_boundary] |
| agreement | agreement | [agreement]habt|habe[/agreement] |
Tools to work with the Merlin corpora from the web
A complete set of Sketch Engine tools is available to work with these Merlin corpora to generate:
- word sketch – collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word and multi-word units
- word lists – lists of nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
- concordance – examples in context
- text type analysis – statistics of metadata in the corpus
Changelog
Merlin Written Learner Corpora
- version merlin_learner_italian (October 2023)
- version merlin_learner_german (October 2023)
- version merlin_learner_czech (October 2023)
Bibliography
MERLIN Corpus
Wisniewski, Katrin; Abel, Andrea; Vodičková, Kateřina; et al., 2018, MERLIN Written Learner Corpus for Czech, German, Italian 1.1, Eurac Research CLARIN Centre, http://hdl.handle.net/20.500.12124/6.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.
