jaTenTen: Corpus of the Japanese Web
The Japanese Web Corpus (jaTenTen) is a Japanese corpus made up of texts collected from the internet. The corpus belongs to the TenTen corpus family which is a set of the web corpora built using the same method with a target size 10+ billion words. Sketch Engine currently provides access to TenTen corpora in more than 30 languages. This jaTenTen Japanese corpus consists of 8 billion words.
Detailed information about TenTen corpora is on the separate page Common TenTen corpora attributes.
Before 2018, the corpus was called jpTenTen.
Part-of-speech tagset
The whole corpus is processed with the MeCab tool (version 0.98), a Part-of-Speech Tagger and Morphological Analyzer, together with the UniDic tool (version 2.1.0). The relevant POS tagset summary is available here.
A small sample of the jaTenTen corpus was tokenized with long unit words. This corpus is named as Japanese Web 2011 sample (jaTenTen11, LUW) with a different POS tagging system.
Special attributes
- 語彙素読み(lemma_kana)
- 活用型(infl_type) > inflected type
- 活用形(infl_form) > inflected forms
jaTenTen corpus in detail
The chart shows the distribution of the parts of speech in the Japanese Web corpus 2011.
Further information about texts in the corpus
Basic information
| Frequency* | |
| Tokens | 10 322 |
| Words | 8 432 |
| Sentences | 442 |
| Web pages | 16 |
* the figures above are rounded to million
Distribution of top-level domains
Tools to work with the Japanese corpus from the web
A complete set of Sketch Engine tools is available to work with this Japanese corpus to generate:
- word sketch – Japanese collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word units
- word lists – lists of Japanese nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
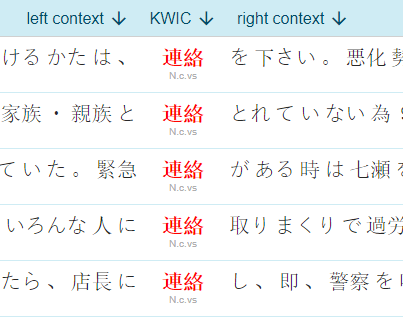
- concordance – examples in context
- text type analysis – statistics of metadata in the corpus
Changelog
version 2.0 (June 2013)
- extended corpus to 8.4 billion words
- tagging corrections (punctuation from Nc.v.s to Supsym, swapped brackets Supsym.b)
- added end of sentence tags after Supsym.p (where missing)
- word sketch grammar version 1.6 and subsequently version 1.7 both of them by Irena Srdanović
version 1.0 (January 2013)
- initial version – 164 million words
Bibliography
Srdanović, I., Suchomel, V., Ogiso, T., & Kilgarriff, A. (2013). Japanese Language Lexical and Grammatical Profiling Using the Web Corpus JpTenTen. In Proceeding of the 3rd Japanese corpus linguistics workshop. Tokyo: NINJAL, Department of Corpus Studies/Center for Corpus Development (pp. 229-238).
Jakubíček, M., Kilgarriff, A., Kovář, V., Rychlý, P., & Suchomel, V. (2013, July). The TenTen Corpus Family. In 7th International Corpus Linguistics Conference CL (pp. 125-127).
Search the Japanese corpus
Sketch Engine offers a range of tools to work with this Japanese corpus.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.

