This page explains how to make your corpus easier to use and more user-friendly. This is especially important if you plan to host your corpus or grant access to other users.
The improvements described below are done in the Configuration file of your corpus.
To access the Corpus configuration, click DASHBOARD – MANAGE CORPUS – Configure – Expert settings – Corpus configuration.
Important note: Any changes to the Corpus configuration require the corpus to be recompiled for the changes to take effect.
Rename corpus and add corpus description
User corpora can be renamed via MANAGE CORPUS – CONFIGURE. Here users can also write a description which will be displayed on the corpus info page.
Another way to edit a corpus name or corpus description is to open the corpus info page and click the pencil icon.
Links to tagset documentation and corpus description pages
Detailed information about the corpus and part-of-speech tagset can be set up in the corpus configuration.
The following lines in the corpus configuration file add links to tagset documentation and corpus description pages.
INFOHREF "https://www.sketchengine.eu/ententen-english-corpus/" TAGSETDOC "https://www.sketchengine.eu/english-tagset"
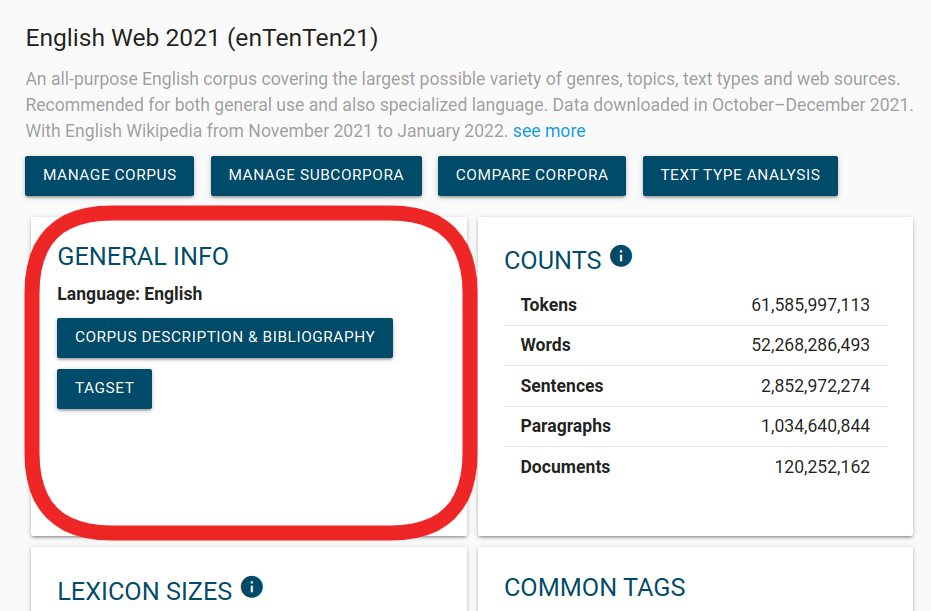
Hide and reorder Text types
By default, the Text type selector displays all structure attributes in your corpus. This is not always desirable. Some automatically generated text types may not be useful and can be hidden. They can also be reordered to display the related text types close to each other. This makes it easier to use the selector, especially if your corpus contains many text types.
Include this line in the corpus configuration file and the text type selector will only show 3 text types in this exact order.
(Hiding text types does not delete them from your corpus, they just do not appear in the Text type selector.)
SUBCORPATTRS "doc.author,doc.genre,doc.year"
This configuration displays only these three attributes listed in SUBCORPATTRS.
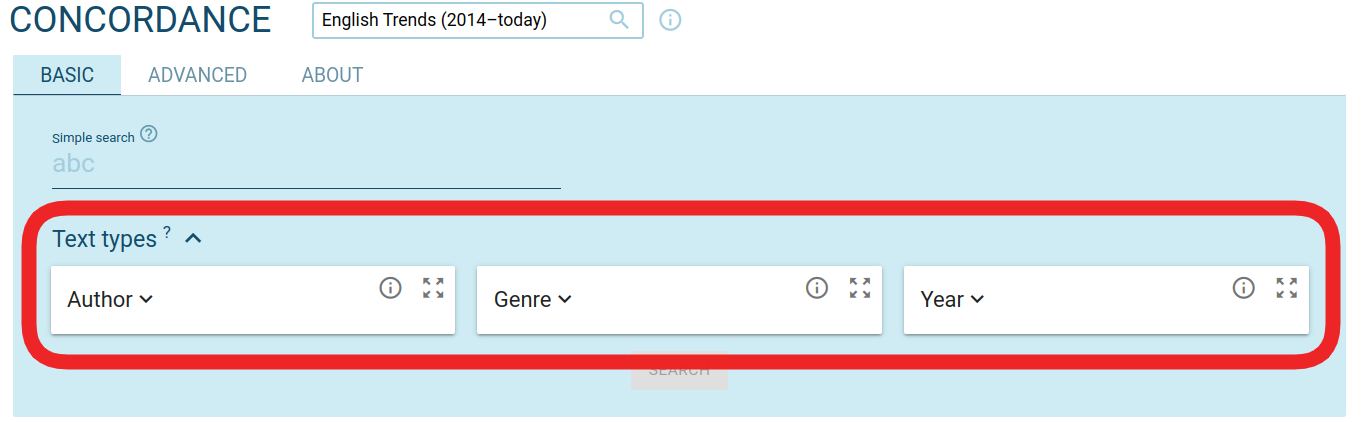
Labels – give text types clear names
Initially, Text type selectors show the automatically generated names (structure attributes) which may look a bit too technical and not always self-explanatory, e.g. tld. You can rename them by including a nicer label (Top level domain) with each attribute, like this:
STRUCTURE doc {
ATTRIBUTE tld {
LABEL "Top level domain (e.g. com)"
...
}
}
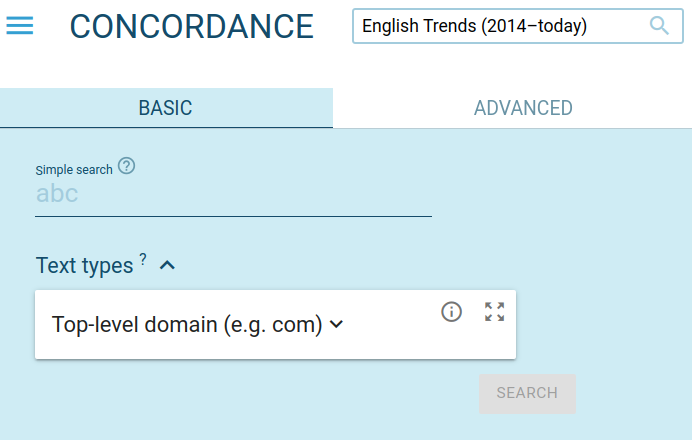
The same applies to structure attributes. (This is only useful if your corpus has some unusual positional attributes, i.e. if it contains something else than the usual attributes word, lowercase, lemma, tag, lempos…)
ATTRIBUTE lc {
DYNAMIC lowercase
DYNLIB internal
ARG1 "C"
FUNTYPE s
FROMATTR word
DYNTYPE index
LABEL "word (lowercase)"
TRANSQUERY yes
}
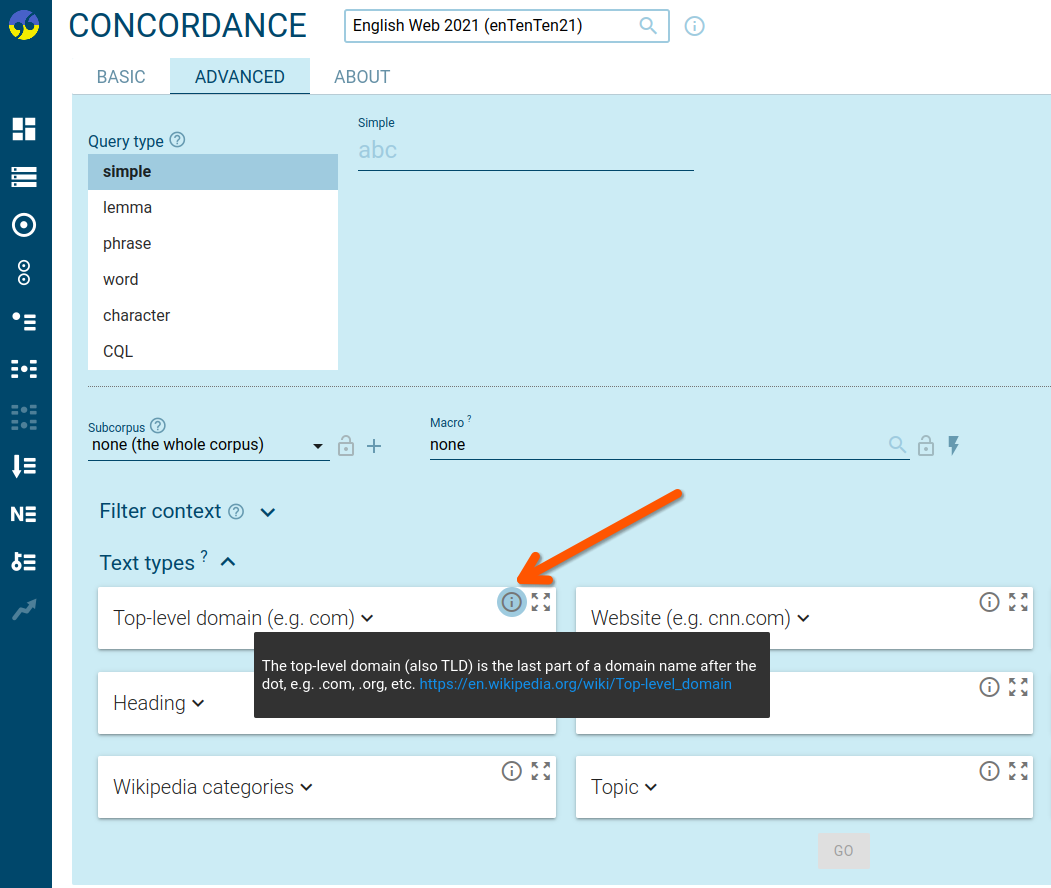
Text type tooltips
Tooltips are displayed when users hover over the info_outline icon. They provide additional information about the text type.
(Similar tooltips can also be created for structure attributes by adding the ATTRDOC line to the attribute in the configuration file.)
STRUCTURE doc {
ATTRIBUTE tld {
LABEL "Top level domain"
ATTRDOC "The top-level domain (also TLD) is the last part of a domain name after the dot, e.g. .com, .org, etc. https://en.wikipedia.org/wiki/Top-level_domain"
}
}
Hide structure attributes
Attributes not be relevant to the corpus can be hidden completely, not only in the tet type selector. To do this, add the # symbol to all the lines in the block related to the attribute. Each block starts with ATTRIBUTE and finishes with a curly bracket }
(The # symbol changes the line into a comment which is ignored during compilation.)
#ATTRIBUTE "website" {
# ARG1 "2"
# DYNAMIC "url3domain"
# DYNLIB "internal"
# DYNTYPE "index"
# ENCODING "UTF-8"
# FROMATTR "url"
# FUNTYPE "i"
# LABEL "Website"
# LOCALE "C"
# MULTISEP ","
# MULTIVALUE "n"
# TYPE "MD_MI"
#}
The above-mentioned example hides the “website” attribute. Remember to comment or delete the attribute in other places of the configuration file (if necessary). For instance, the same attribute might appear in SUBCORPATTRS so it should be deleted from there.
Default line detail in the concordance
To set up the default reference which will be displayed on the concordance result page (on the left side), use the configuration SHORTREF and write a structure attribute or a list of structure attributes.
SHORTREF "=doc.date"
The above configuration will display document year and document website for each concordance line by default.
Users can always change the line details by clicking them or in the View options visibility. Their setting is saved and used as default for the next use of the same corpus.
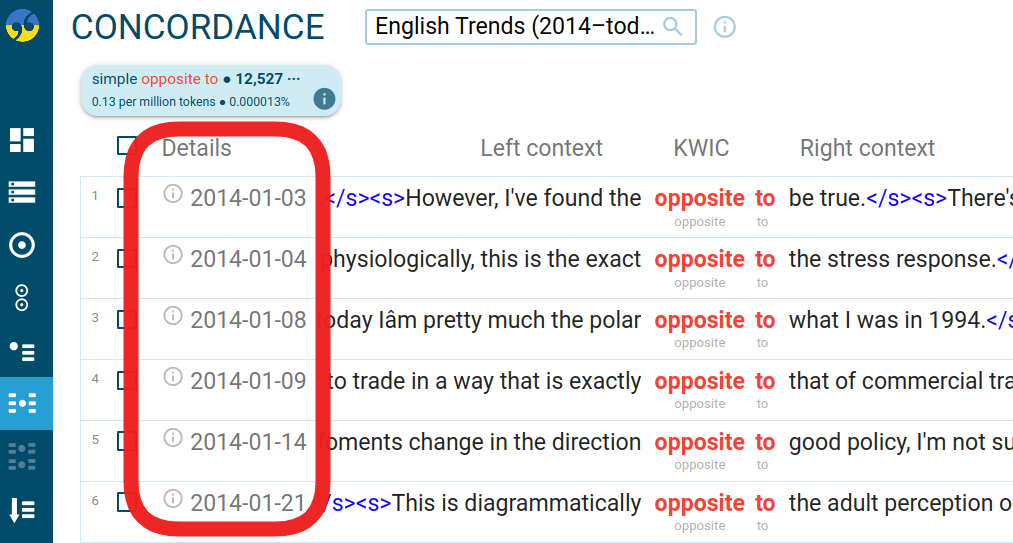
Hierachical text type selector
Text types can refer to the source (newspaper, book, etc.), medium (spoken, written), or any other type of information about the text, and they are assigned to structures inside corpora, e.g. documents or paragraphs. For certain purposes, it might be useful to organize the text types into logical groups such as
genre – fiction – sci-fi
genre – fiction – mystery
Read our documentation on hierarchal headers for more information.
STRUCTURE doc {
ATTRIBUTE genre {
MULTIVALUE "1"
MULTISEP ","
HIERARCHICAL "::"
}
}
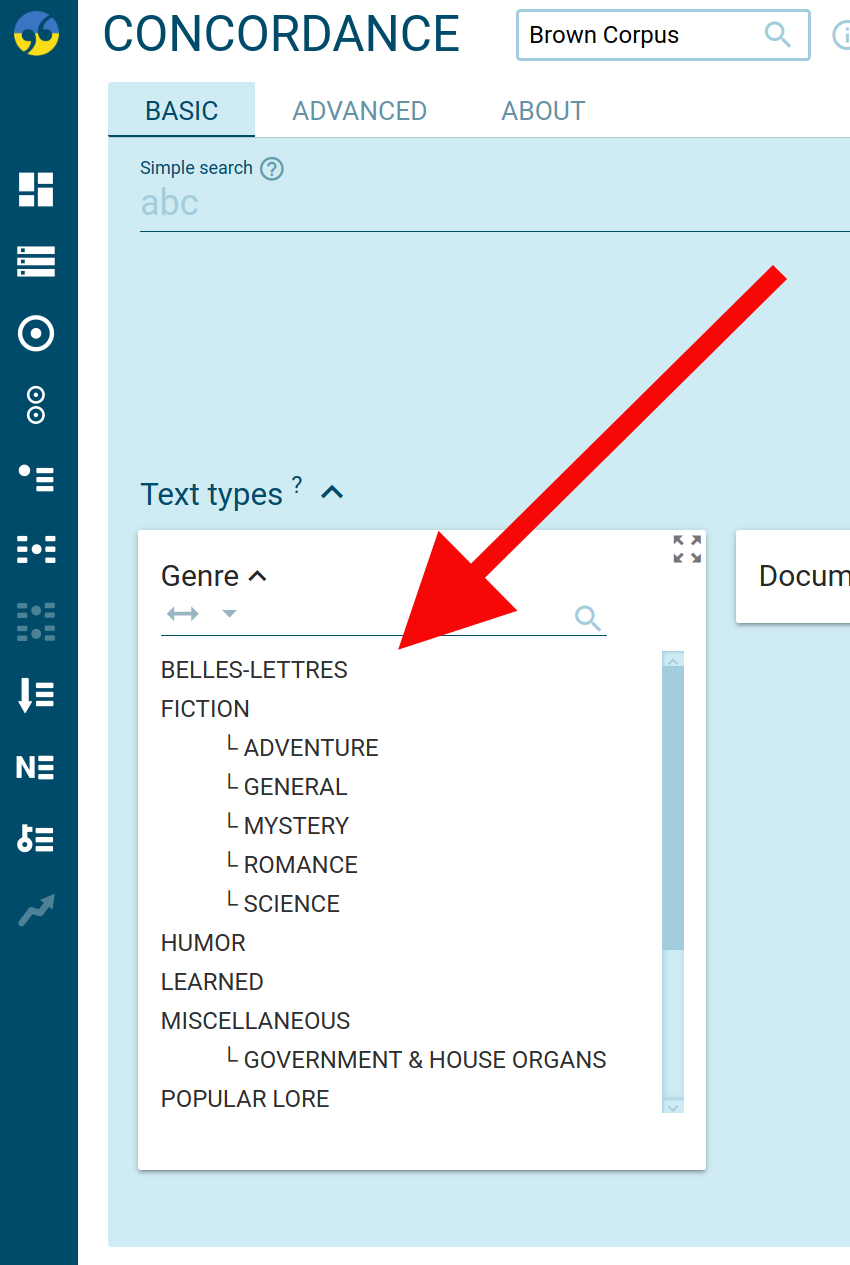
Multimedia (audio, video…)
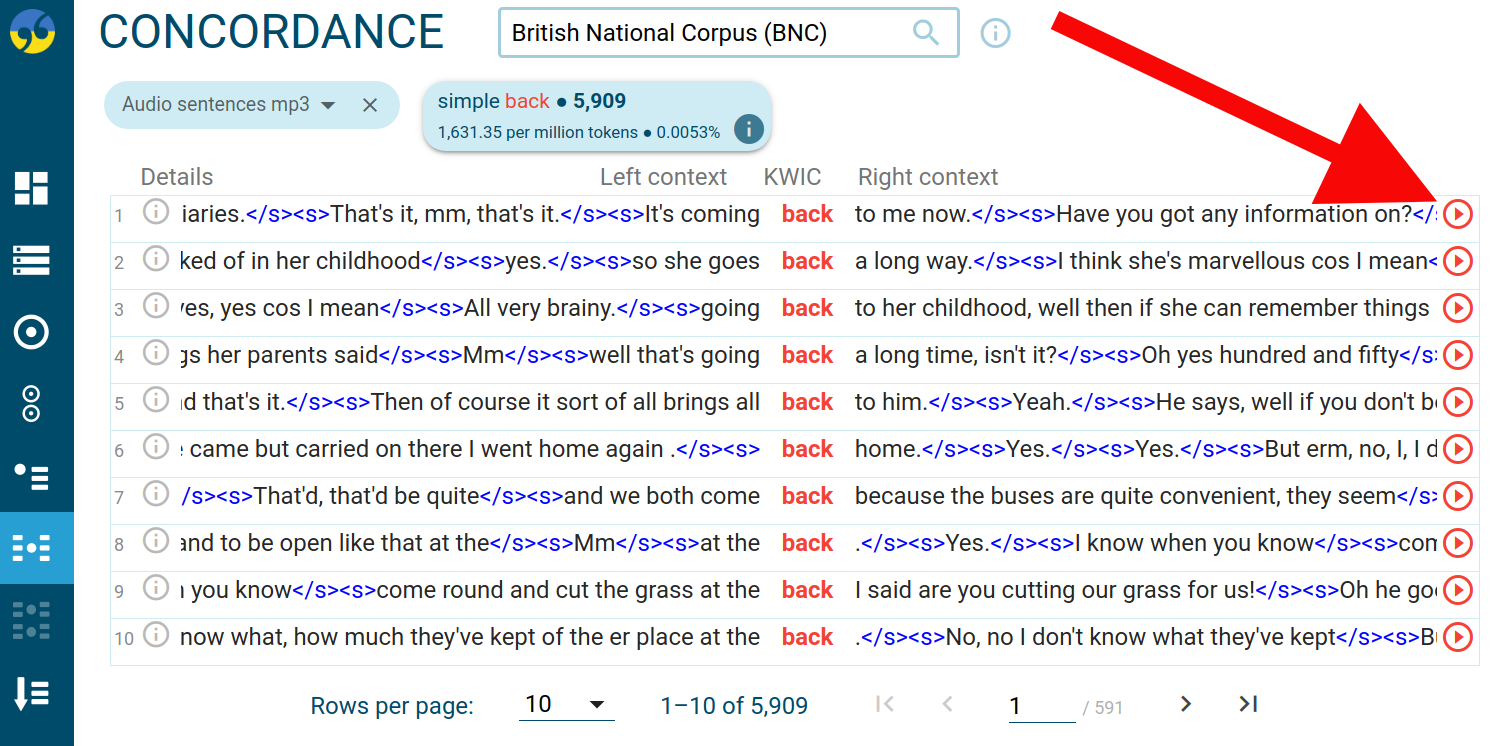
Sketch Engine has support for multimedia corpora, i.e. text corpora with accompanying images, audio recordings, video or other types of multimedia content. Any word, sentence, paragraph, etc. can have a reference to a multimedia file. A multimedia player icon will then appear on the concordance result screen.
To play the multimedia correctly, the file must be publicly accessible on the internet (without login).
Example:
If an audio recording should be added to sentences in the corpus, the corpus configuration section defining the sentence structure should look as follows:
STRUCTURE s {
ATTRIBUTE audio {
URLTEMPLATE "https://drive.google.com/drive/u/0/home/%s"
MEDIATYPE "audio"
}
}
where URLTEMPLATE contains the URL of the location of all the files with the placeholder %s. This placeholder is replaced with the value included as metadata of the sentence in the corpus. MEDIATYPE describes a type of media: audio, image, video.
The corpus data then contain the value which will replace the variable:

The British National Corpus (Sketch Engine login required) is an example of this.
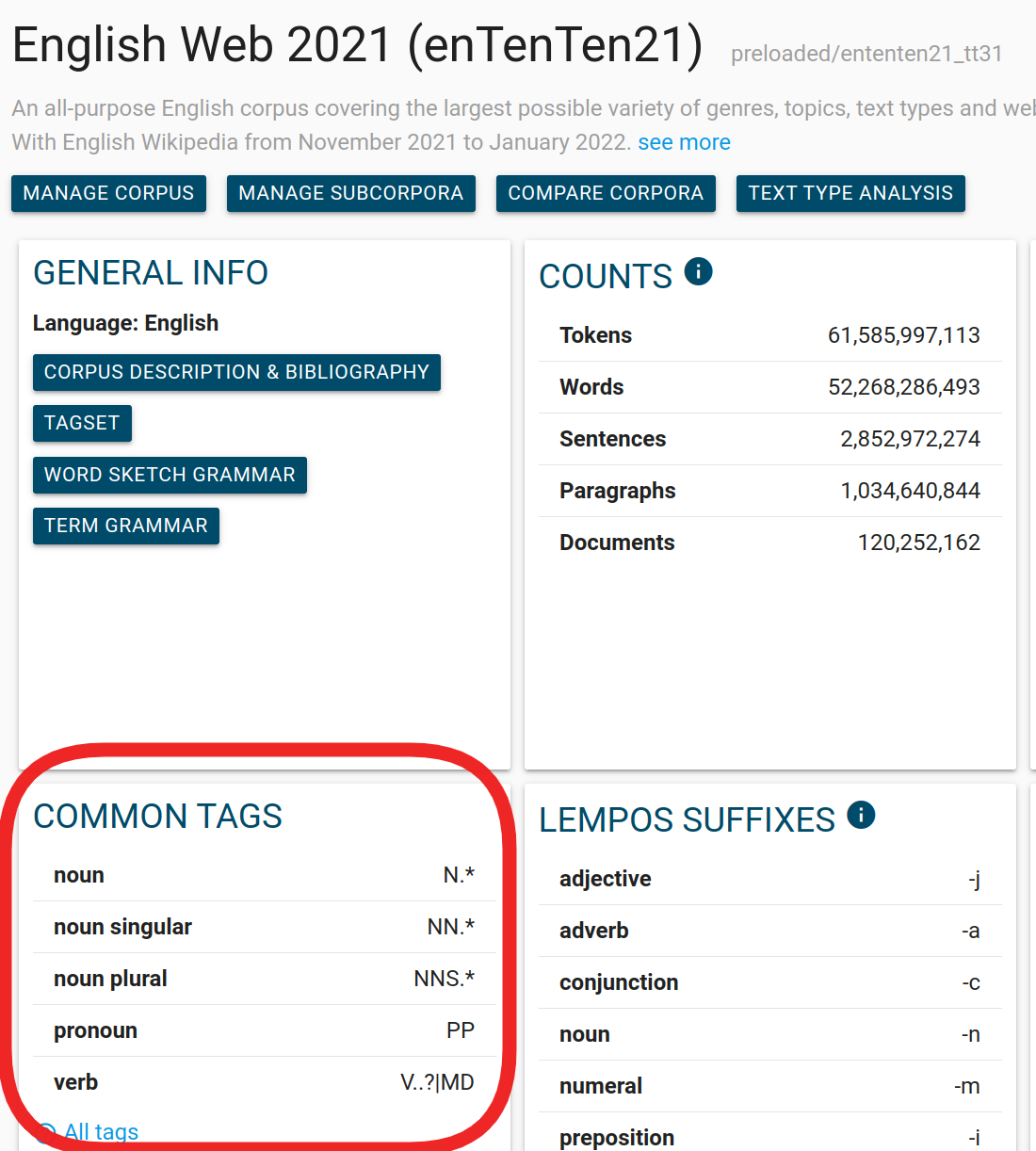
Simplify part-of-speech selection
Common tags table on the corpus info page
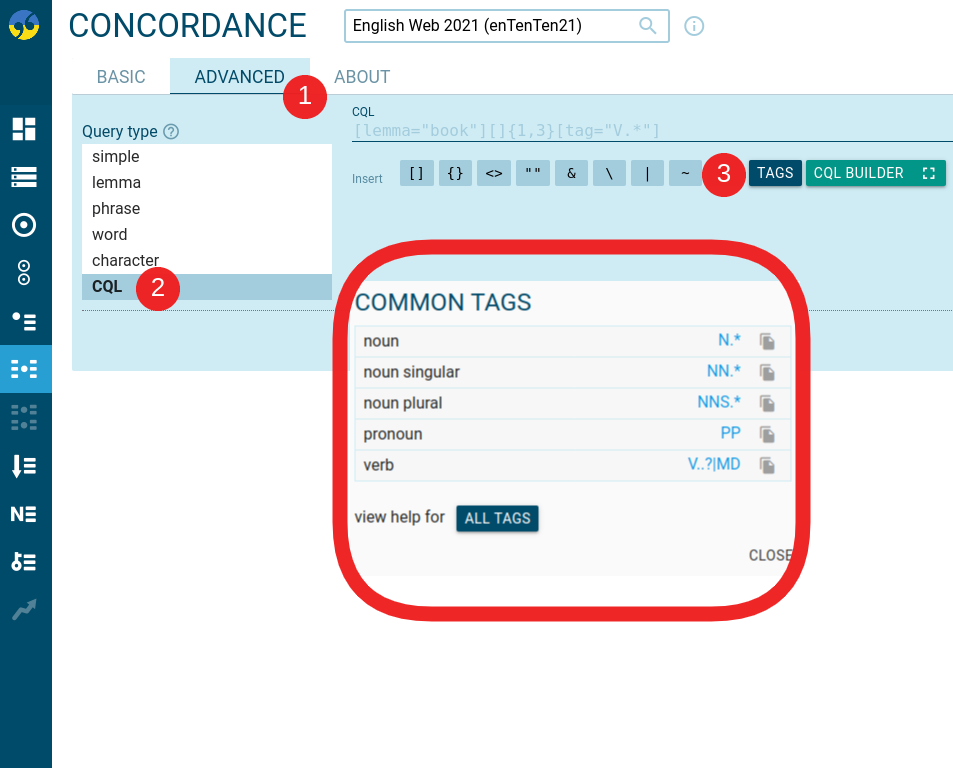
The WPOSLIST is used to include a table of common tags on the Corpus info page and also in the Concordance CQL search to show the regex for the most frequently searched parts of speech.
This configuration consists of pairs of user-friendly name + a regex for the part of speech, separated by commas, e.g.
WPOSLIST ",noun,N.*,noun singular,NN.*,noun plural,NNS.*,pronoun,PP,verb,V..?|MD"
The configuration above will list 5 items in the Common tags table on the corpus info page as well as in Concordance (ADVANCED tab – Query type CQL – TAGS).
 |
 |
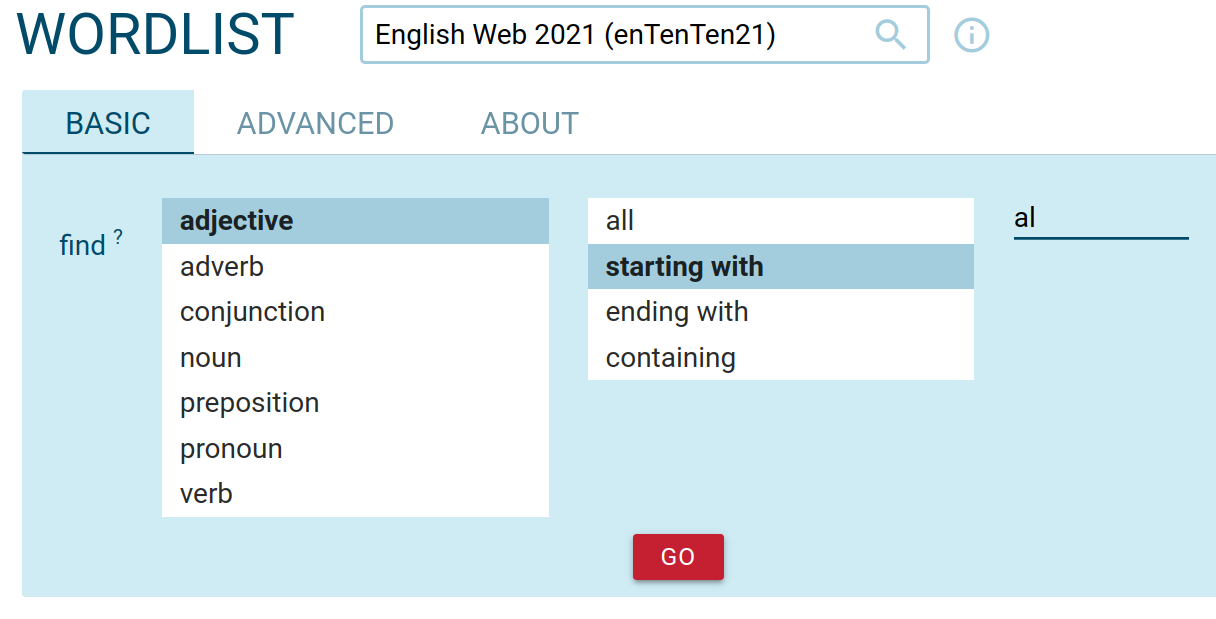
Part-of-speech selector available in word list, concordance, n-grams, etc.
The configuration LPOSLIST will enable users to easily select parts of speech when generating a frequency lists. It also includes a similar selector in the concordance and n-grams.
LPOSLIST ",adjective,-j,adverb,-a,conjunction,-c,noun,-n,preposition,-i,pronoun,-d,verb,-v"
FOR EXPERTS
Users can add more optional settings and additional information to better align corpora with research requirements and preferences. All possible configurations are listed on the page about the Corpus configuration file.
Sharing or hosting corpora
You can host your corpus in the Sketch Engine corpus database or grant access to other users.
OR

