Overview
When studying a word, phrase, or grammatical construction, it is always useful to ask whether it occurs across the varieties of the language, or mostly in one dialect, one domain, or is limited to only informal language. This is why texts (or documents) in a corpus are often labeled with additional information about the origin, context, time, speaker etc. These labels are called text types, sometimes also header information. We follow Biber (1989) in using text type as a generic term for the many ways in which a text might be classified.
Many Sketch Engine features allow the user to limit the analysis to one or a number of text types or to calculate the frequency of a word, phrase or another unit by text type.
Correct text type annotation
These functions only work well if
- the documents in the corpus are classified by text types
- the text type information has a correct format
The basic method is this. The corpus is, we assume, structured as a set of documents. In the vertical file there is a structural unit, let’s call it , for each document. Text type information is associated with the element, as a series of XML, atribute-value pairs, so for example if the text type features are ‘region’ and ‘domain’ and a particular document is Australian and about sports, we might have
<doc region="Aus" domain="sport">
The document content is here.
</doc>
The opening tag is the document’s header. (Attribute names cannot contain characters other than a-z, A-Z, 0-9, underscore. Double-quoting values are mandatory. If they are used, there cannot be any space around the equal sign. The special characters double quote and backslash must be escaped by a backslash (\), e.g. – the double quotes in the document name are preceded by backslashes. ) Also, each feature-value pair specifies a subcorpus of all the documents having that pair: text type information will sometimes also be called subcorpus information.
There may be any number of feature-value pairs. In contrast to approaches to document headers found in, for example, the Text Encoding Initiative, SkE document headers are flat lists of feature-value pairs, not structured objects.
For the Sketch Engine to make the information available for searching, it needs to know about the features: for how they are specified see the list of all features in Corpus configuration.
Recommendations on text type feature design
Usually, when a corpus is prepared for the Sketch Engine, it already comes with some header information. The simplest thing to do is to format that information as feature-value pairs without further review. This does not often work well. Information may have been included in headers for a number of reasons and will often include copyright status or a log of who did what and when, and will often not be complete or consistent. While there is no harm in including the copyright or log information in headers, it is not likely to be of use for linguistic research.
The person preparing the corpus needs to ask “what subcorpora would the users like to be able to specify, in order to constrain their searches?”
And then “is that information already in the headers, and if not explicit, is it implicitly?”
The structure and attribute names in the actual data have to correspond to the corpus configuration file. Note the processing is case sensitive.
Not too many subcorpora, and keep them large
Most corpora only support a limited number of linguistically useful subcorpora, and if subcorpora are to be used to constrain searches, a subcorpus must be quite large, or most searches will return no hits. This fits with a user interface consideration: we want to present the user with a limited number of options, all of which he/she understands, in a single screen. For all of these reasons, as a rule of thumb, we suggest that the team preparing the corpus focus on not more than ten features which are likely to be useful for creating subcorpora, with each feature not having more than ten values, and each feature-value pair accounting for at least 2-3% of the whole corpus.
For example, for the English component of the NCI (New Corpus for Ireland), the features and their possible values are
genre: imaginative, informative
mode: spoken, written
region: Irish, British, American
ie region: North, South, East, West, u
(applies only to Irish English, all else is unclassified)
genre2: arts/culture, business/finance, drama, fiction, govt,
hard/applied-science, information, leisure,
non-fiction, politics, religion/philosophy,
social-science, u
medium: book, conversation, newspaper, official-govt,
periodical, unpublished, website, u
subcorpusbysource:
bnc, gigaword, lexmc, limerick-corp, nitcs, web
While the list displays a range of anomalies, it also shows an attempt to take a range of kinds of materials from a range of types of sources (as listed as values of the last feature; we used several existing corpora as input) into a coherent and usable whole.
Implicit information
There is much information available that is implicit. Two examples: if there is date information available, then a feature for decade can be built. If the corpus spans several decades, then this will be a useful feature for exploring language change. The date feature by itself will have too many values, each accounting for too little data, to be useful.
Second: many corpora are built up from a number of newspapers as well as other sources, with the name of the newspaper held somewhere in the header or filename. But the newspaper name is not directly useful to users for building subcorpora. A ‘medium’ feature that takes the value ‘newspaper’ for all newspaper material will be useful and can be inferred from information that is available.
In sum: the people preparing the corpus need to consider what subcorpora will be useful to their users, and then, to work out how corresponding features can be built for all or most documents, given the information available in the document headers, filenames, or anywhere else.
Hierarchical headers
Some header fields, especially ones with many possible values can be structured into a hierarchy. Provided these headers are set up properly in the corpus, the system can handle a hierarchy and present this within Sketch Engine in a user-friendly way. See below an example of hierarchical headers in Brown corpus:
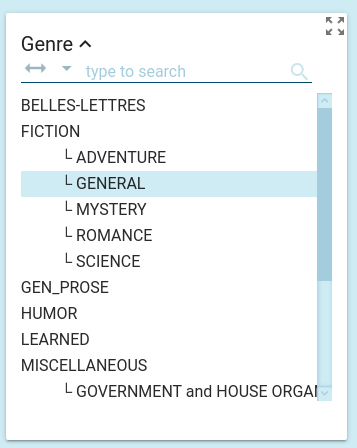
How to set up a hierarchical header
The display in the interface is driven by the data, i.e. by the vertical file. In each header field, all categories must be present that the document belongs to, in form of complete “paths” in the hierarchy. E.g. for a document that belongs to classes “sport”, “sport->football”, “business”, “business->football” and “business->football->manager” the corresponding record will look as follows:
<doc class="sport,sport::football,business,business::football,business::football::manager">
...
</doc>
where ‘,’ is the multivalue separator (can be any character) and ‘::’ is the hierarchy labels separator (can be any string). These two values are specified in the corpus config file.
Also, the hierarchical headers need to be specified as MULTIVALUE in the corpus config file. An example of a hierarchical attribute definition in the corpus config file:
STRUCTURE doc {
ATTRIBUTE domain {
MULTIVALUE "1"
MULTISEP ","
HIERARCHICAL "::"
}
}
Please note that such settings cannot be created by automatic means in the Corpus Architect, you have to edit the corpus config file directly, e.g. by switching the corpus to the expert mode.
Annotation tool
The built-in annotation tool allows adding metadata to documents easily.

Corpus annotation and structures
Read our blog post about corpus annotation and structures in corpora.
